Every few years, the trading industry discovers a new word for the same old problem.
In the 1990s, it was technical analysis: proprietary indicator combinations that worked brilliantly on historical data and struggled in live markets.
In the 2000s, it was quantitative finance: sophisticated models that passed every backtest until the assumptions underlying them broke in 2008.
In the 2010s, it was big data: terabytes of alternative data that predicted earnings until everyone had the same terabytes.
And now, it is artificial intelligence.
Not because machine learning lacks genuine utility in markets. It has real utility. But because the industry's incentive structure — where capital flows to the best backtest, not the best live performance — creates a predictable and recurring fraud.
What Curve-Fitting Actually Means
Imagine you have ten years of historical price data and a model with one hundred adjustable parameters.
Given enough parameters, you can fit that data perfectly. Every twist. Every drawdown. Every recovery. Your model learns the specific sequence of events that occurred in those ten years with extraordinary fidelity.
The problem is that those specific events will not recur. The future has different noise, different regime shifts, different correlations. Your model has not learned pattern. It has memorized history.
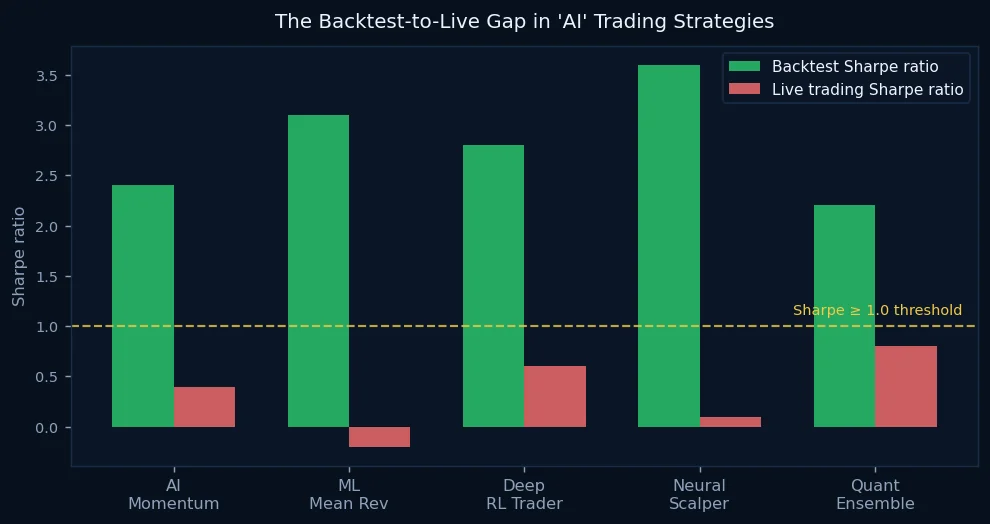
This is the fundamental failure mode of most "AI trading strategies" being marketed to retail investors and even to institutional allocators. The backtest looks extraordinary because the model was optimized on the same data it is being evaluated against. The Sharpe ratio of 2.8 in the backtest becomes 0.4 live — not because the developer was dishonest, but because they were optimizing for the wrong thing.
Why Neural Networks Make This Worse
Classical technical analysis had limited parameters. A moving average crossover system might have two or three variables. You could overfit, but there was a ceiling.
A neural network has thousands to millions of parameters. The capacity to memorize noise is essentially unlimited.
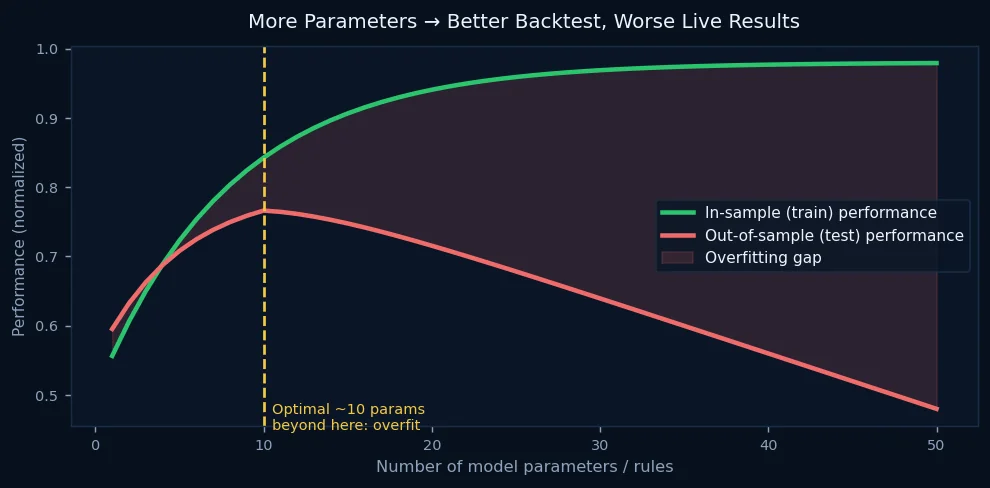
The research literature is unambiguous: in financial time series, which are near-random with low signal-to-noise ratios, complex models with many parameters almost universally overfit. The models that survive out-of-sample testing tend to be simpler than their developers initially wanted them to be.
There is a specific bias that makes this worse in the AI era: selection pressure. When a firm or researcher tries one hundred models and publishes the one that worked, they are not discovering signal — they are discovering which random configuration happened to fit the historical noise. The ninety-nine failed models never see the light of day.
This is why the financial press is full of extraordinary backtests. Extraordinary backtests are easy to generate. Live performance is the only honest ledger.
How to Distinguish Real Edge from Storytelling
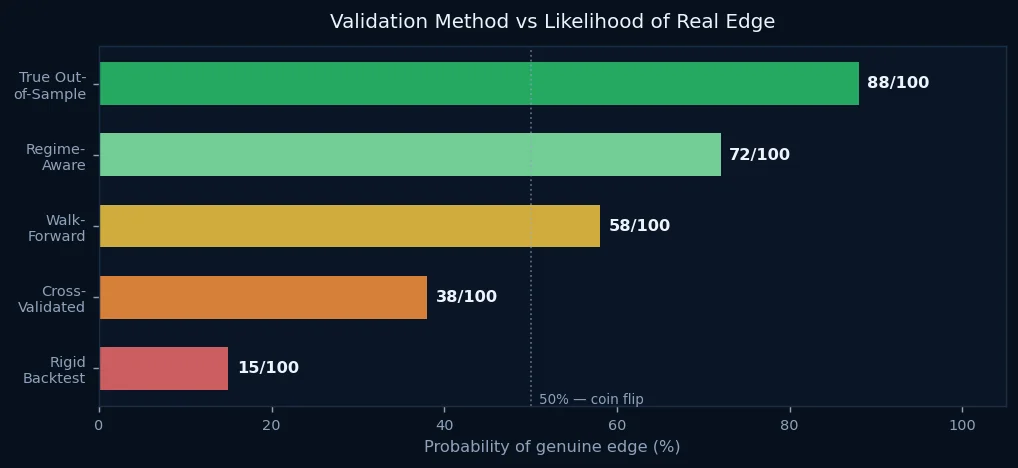
There are concrete questions that separate genuine algorithmic edge from sophisticated curve-fitting:
Does the edge have an economic explanation? Real market edges tend to exist because some structural force creates a persistent pattern — mean-reversion from mechanical liquidity, momentum from investor behavioral bias, seasonality from fund flows. If the only explanation for why a signal works is "the model found it," that is not an explanation.
Was the model evaluated on data it never saw during development? Walk-forward validation — training on a window, testing on what comes next, advancing — is the minimum standard. Models that fail walk-forward almost certainly overfit.
Does performance degrade gracefully as the look-back period shrinks? Genuine edges exist in recent data as well as historical data. If removing the last two years from the backtest dramatically improves performance, the model may have learned a regime that no longer exists.
Is the edge large enough to survive transaction costs? Backtests that assume zero slippage or last-quoted fills are fiction. Algos trading at meaningful size move markets. Models that do not account for market impact are not models — they are simulations of a market that does not exist.
What Separates Real Systematic Trading
The algorithmic strategies that survive long-term are characterized by simplicity, robustness, and economic coherence — not by complexity.
A trend-following system with three parameters that has worked across fifty years and thirty markets is more likely to contain genuine edge than a neural network with forty-seven layers trained on eighteen months of tick data.
The AI era has given traders tools of unprecedented power. Those tools can genuinely improve strategy development, risk management, and execution. But they amplify both signal and noise — and in markets where noise vastly outweighs signal, that amplification is dangerous.
The honest test of a trading strategy has always been the same: Does it make money going forward, on data it has never seen, in conditions that differ from its training environment?
Everything else is storytelling.